












Natūralios kalbos apdorojimas (NLP) toliau tobulinamas naudojant naujus metodus, tokius kaip mokymasis kontekste (ICL), kuris siūlo novatoriškus būdus, kaip pagerinti didelių kalbų modelius (LLM). ICL apima modelių kondicionavimą pagal konkrečius pavyzdžius, tiesiogiai nekeičiant modelio parametrų. Šis metodas ypač vertingas norint greitai apmokyti LLM atlikti įvairias užduotis. Tačiau ICL gali imti daug išteklių, ypač transformatoriumi pagrįstuose modeliuose, kur atmintis reikalauja masto atsižvelgiant į įvesties pavyzdžių skaičių. Šis apribojimas reiškia, kad didėjant demonstracijų skaičiui, labai padidėja skaičiavimo sudėtingumas ir atminties naudojimas, o tai gali viršyti modelių apdorojimo pajėgumus ir turėti įtakos našumui. Kadangi NLP sistemomis siekiama didesnio efektyvumo ir tvirtumo, ICL demonstracijų tvarkymo optimizavimas tapo itin svarbiu moksliniu tyrimu.
Pagrindinė problema, kurią sprendžia ICL, yra tai, kaip efektyviai panaudoti demonstracinius duomenis neišnaudojant skaičiavimo išteklių ar atminties. Tradicinėse sąrankose ICL diegimas buvo pagrįstas visų demonstracijų sujungimu į vieną seką, ty metodą, kuris žinomas kaip concat pagrįstas ICL. Tačiau taikant šį metodą turi būti atskirta kiekvieno demonstravimo kokybė arba aktualumas, o tai dažnai lemia neoptimalų našumą. Be to, sujungimais pagrįsta ICL turi veikti atsižvelgiant į kontekstinius apribojimus, kai tvarkomi dideli duomenų rinkiniai, kuriuose netyčia gali būti nesusijusių arba triukšmingų duomenų. Dėl šio neefektyvumo mokymas reikalauja daug išteklių ir neigiamai veikia modelio tikslumą. Demonstracijų, kurios tiksliai atspindi užduoties reikalavimus, pasirinkimas, o atminties poreikis valdomas, išlieka reikšminga veiksmingo mokymosi kontekste kliūtis.
Sujungimu pagrįsti metodai, nors ir paprasti, turi būti tobulinami, kad būtų galima efektyviai naudoti turimas demonstracijas. Šie metodai sujungia visus pavyzdžius, neatsižvelgiant į kiekvieno svarbą, todėl dažnai atsiranda perteklius ir atminties perteklius. Dabartinės technologijos daugiausia priklauso nuo euristikos, kuriai trūksta tikslumo ir mastelio. Šis apribojimas kartu su didėjančiomis skaičiavimo išlaidomis sukuria kliūtį, trukdantį ICL potencialui. Be to, visų pavyzdžių sujungimas reiškia, kad transformatorių modelių dėmesio į save mechanizmas, kuris keičiasi kvadratiškai pagal įvesties ilgį, dar labiau padidina atminties įtampą. Šis kvadratinio mastelio keitimo iššūkis yra pagrindinė kliūtis, leidžianti ICL efektyviai veikti įvairiuose duomenų rinkiniuose ir užduotyse.
Mokslininkai iš Edinburgo universiteto ir Miniml.AI sukūrė Konteksto besimokančiųjų mišiniai (MoICL) metodas. MoICL pristato naują demonstracijų tvarkymo sistemą, suskirstydama jas į mažesnius specializuotus pogrupius, vadinamus „ekspertais“. Kiekvienas ekspertų pogrupis apdoroja dalį demonstracijų ir sukuria nuspėjamą išvestį. Svorio funkcija, skirta optimizuoti kiekvieno ekspertų pogrupio naudojimą, dinamiškai sujungia šiuos išvestis. Ši funkcija koreguojama pagal duomenų rinkinio ir užduočių reikalavimus, kad modelis galėtų efektyviai panaudoti atminties išteklius. Taigi MoICL suteikia labiau pritaikomą ir keičiamą požiūrį į mokymąsi kontekste, parodydamas reikšmingus našumo patobulinimus, palyginti su tradiciniais metodais.
Mechanizmas, kuriuo grindžiamas MoICL, sutelktas į jo dinaminę svorio funkciją, kuri sujungia ekspertų pogrupių prognozes, kad sudarytų galutinį, išsamų rezultatą. Tyrėjai gali pasirinkti tarp skaliarinių svorių arba hipertinklo, o kiekviena parinktis turi įtakos modelio prisitaikymui. Skaliariniai svoriai, inicijuoti vienodai, leidžia koreguoti kiekvieno eksperto indėlį treniruotės metu. Arba hipertinklas gali generuoti svorius pagal kontekstą ir optimizuoti skirtingų įvesties pogrupių rezultatus. Šis pritaikomumas leidžia MoICL efektyviai veikti su įvairių tipų modeliais, todėl jis yra universalus įvairioms NLP programoms. MoICL skaidymo sistema taip pat sumažina skaičiavimo išlaidas, nes apriboja poreikį apdoroti visą duomenų rinkinį, o ne pasirinktinai teikiant svarbią informaciją prioritetus.
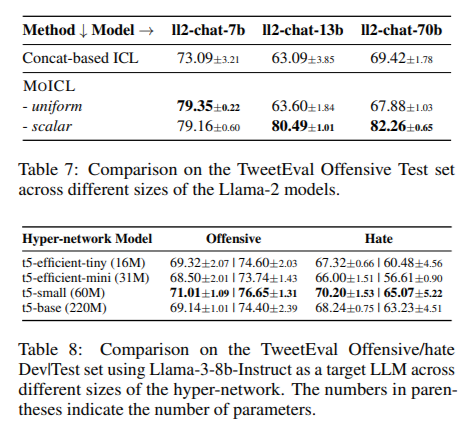
Atliekant septynių klasifikavimo užduočių testus, MoICL nuolat viršijo standartinius ICL metodus. Pavyzdžiui, jis pasiekė iki 13 % didesnį duomenų rinkinių, tokių kaip TweetEval, tikslumą, kur jis pasiekė 81,33 % tikslumą, ir 38 % pagerino triukšmingų duomenų patikimumą. Sistema taip pat parodė atsparumą ženklinant disbalansą (iki 49 % pagerėjimas) ir ne domeno duomenis (11 % geresnis valdymas). Skirtingai nuo įprastų metodų, MoICL išlaiko stabilų veikimą net ir su nesubalansuotais duomenų rinkiniais arba demonstruojant už domeno ribų. Naudodami MoICL, mokslininkai padidino atminties efektyvumą ir greitesnį apdorojimo laiką, įrodydami, kad jis yra efektyvus tiek skaičiavimo, tiek veiklos požiūriu.
Pagrindiniai tyrimo aspektai:
- Našumo padidėjimas: MoICL parodė, kad „TweetEval“ tikslumas pagerėjo iki 13%, palyginti su standartiniais metodais, ir reikšmingai pagerino klasifikavimo užduotis.
- Triukšmo ir disbalanso tvirtumas: Šis metodas pagerino atsparumą triukšmingiems duomenims 38 %, o nesubalansuotas etikečių paskirstymas valdo 49 % geriau nei įprasti ICL metodai.
- Efektyvus skaičiavimas: MoICL sumažino išvadų laiką neprarandant tikslumo, rodydamas duomenų ir atminties efektyvumą.
- Apibendrinimas: MoICL pademonstravo stiprų prisitaikymą prie skirtingų modelių tipų ir NLP užduočių, suteikdamas keičiamo dydžio sprendimą atmintį tausojančiam mokymuisi.
- Tvarkymas už domeno ribų: MoICL yra atsparus netikėtiems duomenų svyravimams, o dokumentais patvirtintas 11 % pagerėjimas valdant ne domeno pavyzdžius.

Apibendrinant galima pasakyti, kad MoICL yra reikšminga ICL pažanga, įveikiant atminties apribojimus ir užtikrinant nuolat didesnį našumą. Naudojant ekspertų pogrupius ir taikant svorio funkcijas, jis siūlo labai efektyvų demonstracinio atrankos metodą. Šis metodas sumažina koncat pagrįstų metodų apribojimus ir užtikrina patikimą įvairių duomenų rinkinių tikslumą, todėl jis yra labai svarbus būsimoms NLP užduotims.
Patikrinkite Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 55k+ ML SubReddit.
(Rėmimo galimybė su mumis) Reklamuokite savo tyrimą / produktą / internetinį seminarą su 1 milijonu ir daugiau skaitytojų per mėnesį ir daugiau nei 500 000 bendruomenės narių
Aswin AK yra MarkTechPost konsultavimo praktikantas. Jis siekia dvigubo laipsnio Indijos technologijos institute, Kharagpur. Jis yra aistringas duomenų mokslui ir mašininiam mokymuisi, turintis tvirtą akademinį išsilavinimą ir praktinę patirtį sprendžiant realaus gyvenimo kelių sričių iššūkius.
Klausykite mūsų naujausių AI podcast’ų ir AI tyrimų vaizdo įrašų čia ➡️












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}